在Google I/O 2024大会上,可谓盛事连连!无论您是热衷于最新的Gemini应用程序更新,还是对开发者即将推出的产品满怀期待,抑或是渴望尝试最新的生成式AI工具,这场盛会都为您准备了丰富的内容。如果您对此持怀疑态度,那么接下来,SDI将为您梳理Google这两天宣布的100项重要事项。(阅读时间预计8分钟)

AI 时刻和模型动力
1.Google推出了Gemini 1.5 Flash,这是一种轻量级模型,旨在为用户提供快速且高效的大规模服务。据称,1.5 Flash是API中提供的最快的Gemini模型。
2.Google显著改进了1.5 Pro模型,使其成为在各种任务中表现总体性能最佳的模型。
3.Google AI Studio 和 Vertex AI 现已提供 1.5 Pro 和 1.5 Flash 的公共预览版,这两款模型均支持高达100万个令牌的上下文窗口。
4.Google的1.5 Pro版本现已通过Google AI Studio和Vertex AI平台,为开发人员提供高达200万个Token Context的上下文窗口支持。
5.Google公布了Project Astra,这是对人工智能助手未来的展望和愿景。

6.Google发布了其第六代定制AI加速器——Trillium,即张量处理单元(TPU)。这是迄今为止性能最高的TPU。
7.与TPU v5e相比,Trillium TPU每芯片的峰值计算性能提升了4.7倍。
8.Google推出的Trillium TPU也是其最可持续的一代产品,相较于TPU v5e,其能效提升了67%以上。
9.Google展示了NotebookLM音频概述的早期原型,该原型使用上传材料的集合来为用户创建个性化的口头讨论。
10.Google宣布,其推出的Grounding with Google Search工具(该工具能够将Gemini模型与世界知识、广泛的可能主题或互联网上的最新信息相连接)现已在Vertex AI上普遍可用。
11.Google在Gemini API和AI Studio中添加了音频理解功能,使Gemini 1.5 Pro现在能够对AI Studio中上传的视频的图像和音频进行推理。
12.从Pixel开始,使用配备多模态功能的Gemini Nano的应用程序将能够像人类一样理解世界——不仅通过文本输入,还能通过视觉、声音和口语等方式。
13.Google发布了Imagen 3,这是迄今为止质量最高的图像生成模型。

14. Google的Imagen 3能够理解提示背后的自然语言和意图,并能有效融合较长提示中的小细节。这一能力使得它能够生成令人难以置信的细节水平,创作出逼真、栩栩如生的图像,并且相较于之前的模型,其分散注意力的视觉伪影明显减少。
15. Google的Imagen 3模型是目前为止渲染文本的最佳模型,这一成就对图像生成领域来说是一个巨大的挑战。
16.Google已向ImageFX中的可信测试人员推出了Imagen 3,感兴趣的用户可以注册加入候补名单。
17. Google Imagen 3 也将于今年夏天登陆Vertex AI 。
18.Google宣布了Veo,这是其迄今为止最强大的视频生成模型。该模型能够生成超过一分钟的高质量1080p分辨率视频,且支持多种电影和视觉风格。

19.未来,Google计划将Veo的一些功能引入YouTube Shorts和其他产品。
20.Google展示了Veo如何通过与电影制作人的合作,为艺术家提供支持——其中包括Donald Glover,他在一个电影项目中尝试了使用Veo。
21.Google重点介绍了Music AI Sandbox,这是一套音乐AI工具,允许用户从头开始创建新的乐器部分,并在不同音轨间传输音乐风格。现在,您可以在YouTube上欣赏到使用这些工具创作的一些全新歌曲,其中包括Wyclef Jean的一首和Marc Rebillet的另一首。

22.Google推出的Infinite Wonderland是一项由艺术家和Google创意人员共同试验的体验,他们微调AI模型,不断重新想象小说“爱丽丝梦游仙境”的视觉世界。在Infinite Wonderland中,读者可以根据每位艺术家的独特风格,为书中1200个句子中的每一个句子生成看似无限的图像。
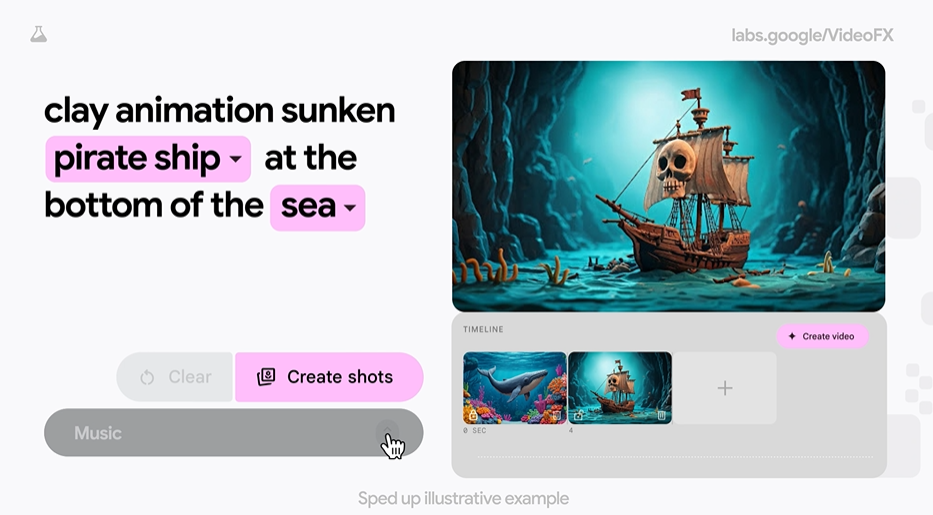
23. Google发布了VideoFX,这是其最新的实验工具,它利用Google DeepMind的生成视频模型Veo,帮助用户将想法转化为视频剪辑。
24.Google的这款产品还配备了故事板模式,使用户能够逐个场景迭代并向最终视频添加音乐。
25.Google在ImageFX应用中增添了更多的编辑控件(满足社区的主要功能需求),用户现在只需简单地滑动图像,即可添加、删除或修改元素。
26. Google的ImageFX将借助Imagen 3技术解锁更多真实感,包括提供更丰富的细节、减少视觉伪影以及实现更准确的文本渲染。
27. MusicFX有一个名为“DJ 模式”的新功能,可帮助您通过组合流派和乐器来混合节拍,利用生成式 AI 的力量将音乐故事带入生活。
28.截至本周,Google的ImageFX和MusicFX已经通过Labs在100多个国家/地区推出。
29.Google已经为Gemini Advanced的订阅者推出了其尖端模型——Gemini 1.5 Pro,现在Gemini Advanced具备了100万个Token Context窗口的能力,足以处理1,500页PDF文件等复杂任务。

30.这也意味着 Gemini Advanced 现在拥有世界上任何商用聊天机器人中最大的上下文窗口。
31.Google在Gemini Advanced中添加了通过Google Drive或直接从用户设备上传文件的功能。
32.很快,Gemini Advanced将能够分析数据,帮助用户快速发现见解,并从上传的数据文件(例如电子表格)中构建图表。
33.对于旅行者来说,有一个好消息:Gemini Advanced新增了一个规划功能,它不仅仅提供建议的活动列表,还能为用户创建一个自定义行程。
34.对于Gemini Advanced的用户来说,Gemini Live提供了一种全新的、移动优先的对话体验,它运用最先进的语音技术来辅助用户与Gemini进行更自然、直观的口语对话。

35.Gemini Live允许用户从10种自然的声音中选择,用来回应;此外,用户可以按照自己的节奏发言,也可以在回答过程中打断并澄清问题。
36. 在Google Messages中的Gemini功能现在允许用户在与朋友发送消息的同一应用程序中与Gemini进行聊天。
37. Gemini Advanced的订阅者很快就能创建Gems,这是为他们梦想中的任何事物而定制的Gemini版本。用户只需描述他们希望Gem做什么以及他们希望它如何响应,Gemini就会接受这些说明并根据用户的特定需求创建Gem。
38.请留意,未来将有更多与Gemini连接的Google工具,包括Google日历、任务、Keep和时钟。
39.Google正在采用专为搜索定制的新Gemini模型,将Gemini的高级功能(包括多步推理、规划和多模态)与其一流的搜索系统相融合。
40.从本周开始,搜索中的人工智能概述将面向美国全体用户推出,并将很快在其他更多国家上线。
41.Google即将在美国搜索实验室的AI概览中推出多步推理功能,支持英语查询。届时,用户无需将问题拆分成多个搜索,而是可以直接提出复杂问题,例如“找到波士顿最好的瑜伽或普拉提工作室,并显示其介绍优惠的详细信息以及从Beacon Hill步行所需的时间”。
42.很快,当用户不熟悉某个主题或希望深入了解某个主题的核心时,他们可以通过选项来调整AI概览,以简化语言或更详细地分解内容。
43.搜索新增了规划功能。例如,定制的膳食和旅行计划将于今年晚些时候在搜索实验室推出,随后还将很快推出派对和健身等更多类别的规划服务。
44.随着视频理解技术的进步,用户现在可以通过视频提问。搜索能够解答复杂的视觉问题,然后解释后续步骤并通过AI概览提供资源。
45.很快,当用户在搜索中寻求新想法时,搜索的生成式人工智能将为其创建一个AI组织的结果页面。用户在搜索餐饮、食谱、电影、音乐、书籍、酒店、购物等类别时,将可以使用这些AI组织的搜索结果页面。
Workspace和照片中来自Gemini模型的帮助
46. Gemini 1.5 Pro现已通过Workspace Labs在Gmail、文档、云端硬盘、幻灯片和表格的侧面板中提供,并计划于下个月向Gemini for Workspace客户和Google One AI Premium订阅者全面推出。

47.用户将能够通过Gmail的侧面板来汇总电子邮件,以获取最重要的详细信息和操作项。
48.除了摘要功能外,Gmail的移动应用程序很快将使用Gemini实现另外两个新功能:上下文智能回复和Gmail问答。
49.在接下来的几周内,Gemini将在Gmail和文档中支持西班牙语和葡萄牙语,以辅助用户的写作。
50.今年晚些时候,在Labs中,用户甚至可以要求Gemini自动整理Drive中的电子邮件附件,生成包含数据的表格,然后使用数据问答功能进行分析。
51. Google Photos中一项名为“Ask Photos”的新实验功能,使用户能够更轻松地查找图库中包含的特定记忆或回忆信息。该功能基于Gemini模型,并将在未来几个月内推出。
52.用户还可以使用“询问照片”功能来创建最近旅行的精彩图库,该功能将自动生成个性化的标题,供用户在社交媒体上分享。
53.从今年晚些时候发布的 Pixel 开始,Gemini Nano(Android的内置设备基础模型)将具备多模式功能。这意味着,除了处理文本输入,Pixel手机还能够理解更多场景、声音和口语等上下文中的信息。

54. Talkback是Android设备的一项辅助功能,旨在帮助盲人和弱视人士通过触摸和语音反馈与设备进行更好的交互。现在,借助具备多模态功能的Gemini Nano,这一功能正在得到进一步改进。
55.即将推出的一项新的、可选择加入的诈骗保护功能,将利用Gemini Nano设备上的AI技术,以隐私保护的方式检测诈骗电话。更多详情将在今年晚些时候公布。
56.Google宣布 Circle to Search 目前可在超过 1 亿台 Android 设备上使用,并且我们有望在今年年底前将这一数字翻倍。
57.很快,用户将能够在Android上使用Gemini创建生成的图像,并轻松地将它们拖放到Gmail、Google Messages等应用中,或者询问正在观看的YouTube视频的相关内容。
58.拥有Gemini Advanced的用户,还可以选择“询问此PDF”功能,快速获取答案,无需翻阅多个页面。
59.学生现在可以借助Circle直接在选定的Android手机和平板电脑上搜索作业帮助。这一功能由LearnLM提供支持,它基于Gemini的新模型系列,并针对学习场景进行了优化。
60.预计在今年晚些时候,Circle to Search将能够处理涉及符号公式、图表、图形等更复杂的问题,为用户提供更全面的搜索体验。
61.Google发布了Android 15的第二个测试版。
62.盗窃检测锁利用Google强大的人工智能技术来感知设备是否被抢走,并快速锁定手机上的信息,保护用户数据安全。
63.即将发布的Android 15将新增私人空间功能,用户可以选择将应用程序置于单独的空间内以确保安全,而进入该空间需要额外的身份验证层。
64.如果单独的锁屏设置无法满足用户对私人空间的需求,用户还可以选择完全隐藏该私人空间的存在。
65.今年晚些时候,Google Play Protect 将使用设备上的人工智能技术,帮助用户发现试图隐藏其行为以进行欺诈或网络钓鱼的应用程序。
66.Google将通过 Google Messages 中的 RCS 为日本带来更新的消息传递体验。
67.Google将在美国推出一个功能,允许用户创建仅包含文本的数字版本通行证。用户只需拍摄一张通行证(如保险卡或活动门票)的照片,然后轻松将其添加到Google电子钱包中,即可实现快速访问。
68.Google展示了如何在Google地图中直接提供增强现实内容,为与三星和高通合作构建的Android生态系统扩展现实(XR)平台奠定了坚实基础。
69.现在,用户可以在Max和Peacock上观看喜爱的节目,或者在搭载内置Google服务的精选汽车上畅玩“愤怒的小鸟”游戏。
70.Google计划在未来几个月内将Google Cast引入搭载Android Automotive OS的汽车中,首先选择Rivian品牌,这样用户将能够轻松地将手机上的视频内容投射到汽车屏幕上。

71.今年晚些时候,搭载Wear OS 5的手表将实现电池寿命优化。举例来说,与搭载Wear OS 4的手表相比,跑户外马拉松时,其电量消耗将最多减少20%。
72. Wear OS 5 还将为健身应用程序提供支持更多数据类型的选项,例如触地时间、步幅和垂直摆动。
73.借助Google的Gemini模型,用户现在可以更轻松地通过人工智能生成的个性化描述来选择在Google TV和其他Android TV操作系统设备上观看的内容。
74.这些由人工智能生成的描述还能够为电影和节目提供缺失或尚未翻译的描述。
75.有一个有趣的统计数据显示,自从该服务推出以来,用户已经建立了超过10亿个快速配对连接。
76.本月晚些时候,用户将能够通过快速配对功能,在“查找我的设备”应用程序中使用Chipolo和PebbleBee(未来还将有更多合作伙伴)的蓝牙跟踪器标签来连接并查找钥匙、钱包或行李等物品。
77.参赛者可以参与Gemini API 开发者竞赛,发掘最具创新和实用价值的人工智能应用。本次竞赛的奖品设置为一辆经过电动改装的定制版1981年德罗宁汽车。
78.Google推出了PaliGemma,这是他们首个针对视觉问答和图像字幕进行优化的视觉语言开放模型。
79.Google 展示了Gemma的下一代版本,即Gemma 2。它采用了全新的架构,并计划引入一个拥有27B参数的更大实例。据悉,这一实例的性能甚至超越了两倍大小的模型,且能够在单个TPU主机上高效运行。

80. Gemini模型现已支持在Android Studio、IDX、Firebase、Colab、VSCode、Cloud以及IntelliJ IDEA等多个开发工具中,帮助开发人员提升工作效率。
81. Google计划在今年晚些时候在Android Studio中推出Gemini 1.5 Pro。这款模型配备了一个大的上下文窗口,旨在提供更高质量的响应,并解锁多模式输入等多样化用例。
82. Google AI Studio 现已在包括英国和欧盟在内的 200 多个国家/地区上线。
83. Gemini API 现在支持并行函数调用和视频帧提取。
84.Google即将在下个月推出的Gemini API中引入新的上下文缓存功能,该功能允许用户以较低的成本缓存常用的上下文文件,从而简化大型提示的工作流程。
85. Android 平台现提供对 Kotlin 多平台的一流支持,协助开发人员跨平台共享应用程序的业务逻辑。
86.Firebase 支持的可调整大小模拟器、Compose UI 检查模式以及 Android Device Streaming 均为新推出的产品,旨在协助开发人员为各种外形尺寸的设备构建应用程序。
87.从 Chrome 126 开始,Gemini Nano 将内置于 Chrome 桌面客户端中。
88.Google现已推出多页面应用程序的视图转换API(这是一项备受期待的功能),它允许开发人员轻松构建出平滑、流畅的类似应用程序的导航,不论站点架构如何。
89. Google推出了Project IDX,这是一项针对全栈、多平台应用程序的全新集成开发人员体验,现已面向所有人开放尝试。
90. Firebase 发布了 Firebase Genkit 测试版,这款工具将帮助开发人员更轻松地将其应用程序集成生成式 AI 体验。
91. Firebase 还发布了 Firebase Data Connect,这是将 SQL 与 Firebase 结合使用的新工具(通过 Google Cloud SQL)。这一创新工具不仅将 SQL 工作流程引入了 Firebase,还显著减少了开发人员需要编写的应用代码量。

92.Google 与 James Manyika、Jeff Dean 和 Koray Kavukcuoglu 就支持 AI 的技术和研究进行了深入讨论,旨在让开发人员更深入地了解这些技术和研究。
93. Google正在采用一种名为“人工智能辅助红队”的新技术来强化其红队测试能力——这是一种经过验证的方法,旨在主动检测自身系统的潜在弱点并尝试突破它们。
94.Google 还将 SynthID 扩展到了两种新的模式:文本和视频。
95. 在未来几个月内,Google将通过其更新的 Responsible Generative AI 工具包,将SynthID文本水印技术开源。
96.Google发布了LearnLM,这是一系列基于Gemini并针对学习进行了优化的新模型。LearnLM已经为Google的多项产品功能提供了支持,这些功能包括Gemini、搜索、YouTube以及Google Classroom。

97.Google计划与哥伦比亚师范学院、亚利桑那州立大学、纽约大学蒂施分校和可汗学院等机构的专家展开合作,以进一步完善和扩展LearnLM模型,并将其应用于更多非自有产品之中。
98.Google与MIT RAISE合作开发了在线课程,旨在帮助教育工作者在课堂上高效运用生成式人工智能。
99.Google开发了一款名为Illuminate的新实验工具,旨在使知识更容易获取和消化。
100. 推出的lluminate能够生成基于人工智能技术的对话,这些对话由两个虚拟声音组成,旨在为用户提供研究论文中关键见解的概述。感兴趣的用户现在即可在labs.google网站上注册并试用。

内容参考:https://blog.google/technology/ai/google-io-2024-100-announcements/